Customizing the Solr Config in the Drupal admin interface involves making changes to the Solr server settings.
1) Once you are in the admin dashboard, look for the Configuration tab, find the section Search and metadata and click on the subsection Search API.
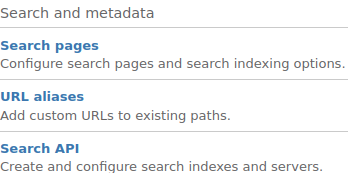
Figure 1: The subsection Search API contains configuration of WissKI content indexed with Solr.
2) Below you will see a list of indexes grouped by the server they are associated with. Click on the Edit operation of the server that you want to customize.
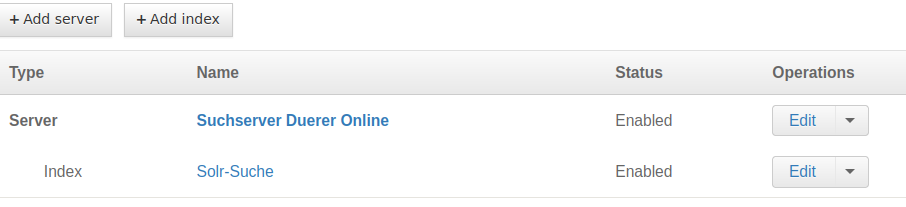
Figure 2: Solr manages structured (formatted) and unstructured data provided by the server.
3) Different tabs representing various aspects of the Solr configuration. For example, you can add or remove fields, adjust tokenization process, define custom analyzers and set up faceted search options. You can also manage stopwords, synonyms and other text processing features there.
4) Some changes may require importing relevant config files, restarting Solr server and rebuilding the search index to reflect the modifications in the search results.
Customization of Analyzers
In Drupal, you can customize Solr analyzers through the administration menu using JSON files specific to each Field Type. Each Field Type is associated with two analyzers – one for the indexing and another for the querying process. It‘s essential to modify both analyzers consistently to ensure that search queries match the data that has already been collected and indexed.
1) A click on the Custom field type tab will takes you to a list of Field Types that you can customize. Find the Field Type you want to modify and click on the Edit link next to it.
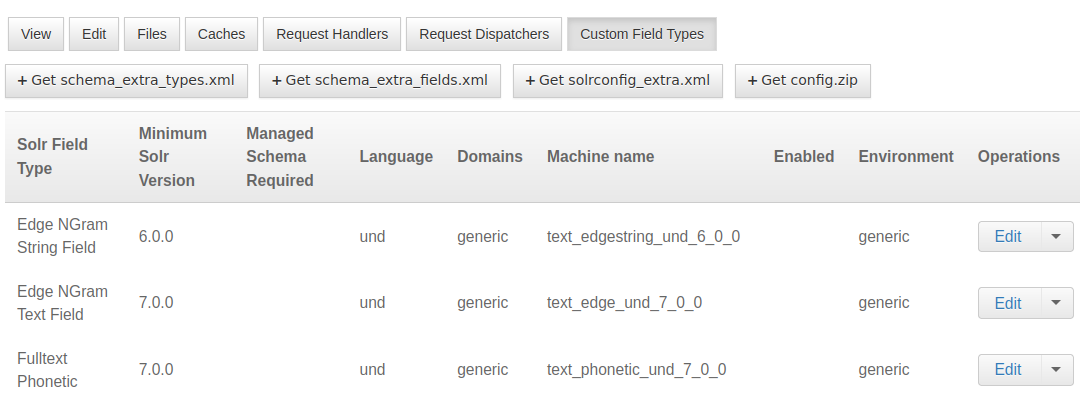
Figure 3: Text Field Types in Solr search play a crucial role in how textual data is indexed, analyzed, and processed for search queries.
2) By opening the FieldType section and enabling the check box labeled I know what I‘m doing, you gain access to the text field with the JSON configuration for the analyzers.
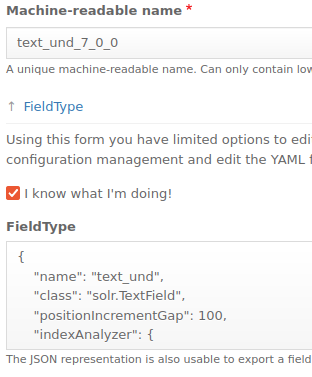
Figure 4: JSON configuration utilized to customize the indexing and searching analyzers based on the chosen Field Type.
Example ICUNormalizer2CharFilterFactory
The ICUNormalizer2CharFilterFactory in Solr utilizes the ICU (International Components for Unicode) Library to achieve text normalization. The ICU Library offers functionality for text, processing, collation and internationalization, making it an ideal choice for handling Unicode.
Unicode normalization ensures that different representations, such as NFD, NFC, NFKD and NFKC for the same character with diacritical marks (e.g. Ç, é, Å) are handled consistently. This process involves tasks like removing unnecessary whitespaces, converting text to lowercase, eliminating accents, among other transformations.
The following example demonstrates how normalization guarantees that two strings, which use different binary representations for their characters during searching and indexing are equivalent in terms of their normalization form. As a result, data recorded differently from what was searched for can still be found.
Use Case of character „Ç“
The Unicode representations of two versions of character „Ç“. Both „\u00C7“ and „\u0043\u0327“ produce the same visual character: „Ç Ç“. However, a direct comparison of the Unicode strings would yield „False“:
print("\u00C7", "\u0043\u0327") => Ç Ç
"\u00C7" == "\u0043\u0327" => False
"Ç" == "Ç" => False
Normalization ensures two strings with different binary representation for their characters will have the same binary value after normalization. For instance, when using the NFKD (Normalization Form Compatibility Decomposition) normalization form:
unique = "\u00C7"
merged = "\u0043\u0327"
unicodedata.normalize( "NFKD", unique ) == unicodedata.normalize( "NFKD", merged ) => True
Analyzers configuration
In Drupal, the ICUNormalizer2CharFilterFactory should be added and adjusted to the JSONs of the analyzers for the following Field Types:
-
text_edge_und_*
-
text_en_*
-
text_de_*
-
text_und_*
-
text_ngram_und_*
1) To customize the Field Types through the admin dashboard, navigate to the
Configuration > Search API > Edit server-operation > Custom Field Types
and click on Edit for each Solr Field Type you want to modify.
2) Expand the FieldType section to access the JSON of analyzers.
3) Activate the check box I know what I‘m doing.
4) Add a class as the first element in the charFilters array for both indexAnalyzer and queryAnalyzer in the expanded text area:
{
„class“: „solr.ICUNormalizer2CharFilterFactory“
}
5) Here is a full JSON configuration after changing the Field Type „text_de_*“.
{
"name": "text_de",
"class": "solr.TextField",
"positionIncrementGap": 100,
"indexAnalyzer": {
"charFilters": [
{
"class": "solr.ICUNormalizer2CharFilterFactory"
},
{
"class": "solr.MappingCharFilterFactory",
"mapping": "accents_de.txt"
}
],
"tokenizer": {
"class": "solr.WhitespaceTokenizerFactory"
},
"filters": [
{
"class": "solr.WordDelimiterGraphFilterFactory",
"catenateNumbers": 1,
"generateNumberParts": 1,
"protected": "protwords_de.txt",
"splitOnCaseChange": 0,
"splitOnNumerics": 1,
"generateWordParts": 1,
"preserveOriginal": 1,
"catenateAll": 0,
"catenateWords": 1,
"stemEnglishPossessive": 0
},
{
"class": "solr.LengthFilterFactory",
"min": 2,
"max": 100
},
{
"class": "solr.LowerCaseFilterFactory"
},
{
"class": "solr.DictionaryCompoundWordTokenFilterFactory",
"dictionary": "nouns_de.txt",
"minWordSize": 5,
"minSubwordSize": 4,
"maxSubwordSize": 15,
"onlyLongestMatch": false
},
{
"class": "solr.StopFilterFactory",
"ignoreCase": true,
"words": "stopwords_de.txt"
},
{
"class": "solr.SnowballPorterFilterFactory",
"protected": "protwords_de.txt",
"language": "German2"
},
{
"class": "solr.RemoveDuplicatesTokenFilterFactory"
}
]
},
"queryAnalyzer": {
"charFilters": [
{
"class": "solr.ICUNormalizer2CharFilterFactory"
},
{
"class": "solr.MappingCharFilterFactory",
"mapping": "accents_de.txt"
}
],
"tokenizer": {
"class": "solr.WhitespaceTokenizerFactory"
},
"filters": [
{
"class": "solr.WordDelimiterGraphFilterFactory",
"catenateNumbers": 0,
"generateNumberParts": 1,
"protected": "protwords_de.txt",
"splitOnCaseChange": 0,
"generateWordParts": 1,
"preserveOriginal": 1,
"catenateAll": 0,
"catenateWords": 0
},
{
"class": "solr.LengthFilterFactory",
"min": 2,
"max": 100
},
{
"class": "solr.LowerCaseFilterFactory"
},
{
"class": "solr.SynonymGraphFilterFactory",
"ignoreCase": true,
"synonyms": "synonyms_de.txt",
"expand": true
},
{
"class": "solr.StopFilterFactory",
"ignoreCase": true,
"words": "stopwords_de.txt"
},
{
"class": "solr.SnowballPorterFilterFactory",
"protected": "protwords_de.txt",
"language": "German2"
},
{
"class": "solr.RemoveDuplicatesTokenFilterFactory"
}
]
}
}
6) After making the necessary changes to the Solr configuration, you should proceed with the usual steps of downloading the updated configuration (Get config.zip) and then importing it into Solr. This ensures that the modified configuration takes effect and is applied to the Solr search engine.
Figure 5: To customize the behavior of Solr search several XML and JSON configuration files come into play.
Customization of Stop Word List
In Solr, a stop word is a common word, like „a“ or „the“ that have little or no value in a search query, because it appears frequently in the text and does not contribute to the overall meaning.
1) Within a Field Type configuration, find the Text Files section. This section contains various text areas where you can define settings related to the text processing.
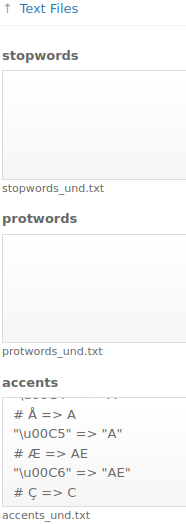
Figure 6: Text analysis techniques establish rules for reducing the information, breaking down textual content into units, and filtering out low-information words.
2) Customize the Stop Word List by adding or removing words in the stopwords text area. Each word should be listed on a separated line. Comment lines start with „#“.
# Custom Stopwords for Field Type "text_en_*"
the
and
or
Use Case for instance in German language
The default Stop Word List filter out important words like „will“ while searching for the name „Will“. By clearing or modifying it, you can ensure that relevant words are not excluded from the search results.
Happy searching!