
Eingeläutet vom ersten Nürnberger Schnee begann das diesjährige WissKI Anwendertreffen im Germanischen Nationalmuseum. An zwei Tagen trafen sich WissKI Nutzer*innen, Entwickler*innen und Interessierte, um Projekte und Entwicklungen vorzustellen, sich auszutauschen, zu diskutieren und künftige Aufgaben auszuhandeln.
Den ersten Tag begann Robert Nasarek mit einer Keynote über Drupal, WissKI und die WissKI Community. (Präsentation)
Mit den Konsortien der NFDI4Culture, NFDI4Objects und NFDI4Memory erfährt auch Linked Open Data und damit semantische Datenmodellierung neuen Aufwind. Forschungsdatenmanagent sei eine komplexe Aufgabe durch das Zusammenführen verschiedener Bedürfnisse und Drupal als Framework halte nachwievor ein gute Balance zwischen Einfachheit, neuesten Entwicklungen und Performance auf der einen Seite und Flexibilität, Sicherheit, Maintainbarkeit und Individualisierung auf der anderen Seite. WissKI erfreue sich einer steigenden Beliebtheit durch seinen elaborierten Ansatz zur Erzeugung von FAIRen Daten, seiner Integration verschiedenster Medien, seinem holistischen Einsatz in Bezug auf den Forschungsdatenlebenzyklus und gleichzeitigen agnostischen Ansatz in Bezug auf Drittanbieter Software, Bibliotheken, Module und Erweiterungen.
Mit Drupal 10.2 kommen auch neue Features hinzu, unter anderem der Project Browser und Automatic Updates, darüber hinaus erhalten die Field UI und die Admin Toolbar ein neues Erscheinungsbild.
WissKI sei inzwischen komplett Drupal 10 bereit und schaue schon auf Drupal 11; zum Ende des Jahres starte die WissKI Cloud und neue Wege der Performancesteigerung werden vorgestellt. Darüber hinaus haben sich verschiedene Initiaten zur Erstellung von Basispathbuildern und Minimaldatenmodellen gebildet.
Chat.wiss-ki.eu habe sich zum maßgeblichen Forum und Austauschplattform entwickelt, Weeklies haben sich als offene und gemeinschafliche Arbeitssessions etabliert und Quaterlies finden jetzt alle drei Monate als allgemeines informelles Forumsformat statt.
Letztlich gibt es tolle Neuigkeiten vom CIDOC-CRM, jede stabile Version wird jetzt auch in OWL implementiert und kann direkt importiert werden.
Anschließend präsentierte Georg Hohmann die Interessengemeinschaft für semantische Datenverarbeitung e. V.
Der IGSD sei ein Verein, der sich für Ausbau und Förderung von semantischer Datenvernetzung einsetze und vor allem die Nutzung bzw. den Einsatz semantischer Technologien, Linked Data, Open Source und Open Access fördere. Darüber hinaus biete er Services rund um WissKI an und fungiere auch als Organisationsform für wissenschaftliche Projektförderung. Freundlicherweise übernahm der Verein die Tagesverpflegung für das Anwender*innentreffen!
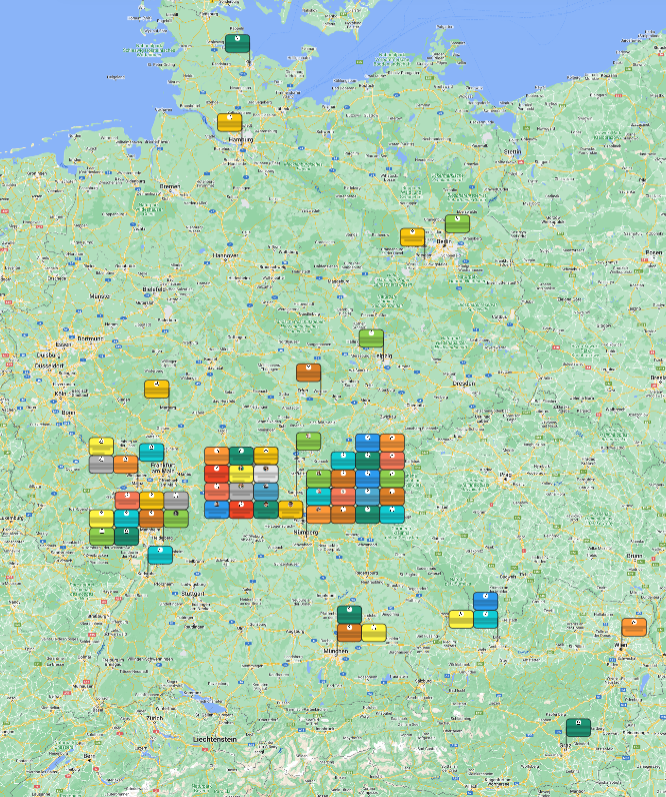
Einen kurzen Überblick über die Community ermöglichte Robert Nasarek mit einer Karte und der Auswertung einer Umfrage.
Das diesjährige Anwender*innentreffen wurde überwiegend von Angehörigen von Institutionen (online) besucht, die in Nürnberg, Erlangen und Heidelberg beheimatet sind, aber auch User*innen aus Berlin, Frankfurt/Main, Hamburg, Karlsruhe, Kiel, Mainz, Marburg, München, Potsdam, Weimar, Graz, Linz und Wien waren dabei! Insgesamt konnten wir uns über 23 Personen im Saal und 51 Personen im Online-Channel freuen!
In einer nicht-repräsentativen Umfrage konnten wird uns ein kleines Bild von den Anwender*innen, ihren Bedürfnissen und Arbeitskontext verschaffen anhand von 25 antwortenden Personen erstellen.
Der überwiegende Teil der Befragten verwendete WissKI im Bereich von Museen und Sammlungen (33,3%), Kunstgeschichte (29,2%), im Archivwesen (20,8%) und Bibliothekswesen (20,8%), wobei die Nutzer*innen zwischen drei bis zehn Jahren mit WissKI arbeiten (40%), rund ein Drittel (32%) ein bis drei Jahre und ein Viertel (24%) unter einem Jahr.
Die meisten übernehmen dabei Aufgaben der semantischen Datenmodellierung (48%), des Sitebuildings/ der Redaktion (40%) oder im Projektmanagement (28%).
Fast die Hälfte (43,9%) der Projekte umfasst 2 bis 3 Personen, ungefähr jeweils ein Viertel der Projekte sind Solounternehmungen (28,6%) oder mit 4 bis 10 Personen besetzt (23,8%).
Dem Großteil (68,2%) steht qualifiziertes IT-Personal mit weniger als 10 Wochenstunden zur Verfügungen, aber 13,6% der Projekte werden auch mit 30 bis 40 Wochenstunden unterstützt.
Interessant sind die Präferenzen für vorgegebene Softwarefeatures und -eigenschaften (unabhängig von WissKI).
Ein Großteil finden eher wichtig bzw. sehr wichtig Kosten (95,8%), breite Import- und Export-Möglichkeiten (87,5%), Einstellungsmöglichkeiten für Sicherheit, Benutzerrollen und Rechte (87%), flexible Dateneingabe und Darstellungsmöglichkeiten (83,3%), die einfache Einrichtung von Schnittstellen (82,6%), Möglichkeiten der Performancesteigerung (82,6%), eine erweitere Konfiguration der Suche (82,6%), die Möglichkeit der semantische Datenmodellierung (75%), die Integration von Normdaten (75%), eine geführte Installation (72,8%) und eine breite Medienintegration (70,9%), wogegen das Vorhandensein von Vorlagen und Templates nur 39,1% eher wichtig oder sehr wichtig einschätzen.
Um sich zu informieren und auszutauschen halten die meisten Befragten informellen Kontakt zu anderen Personen der Community (91,7%), die Häfte besuchen die News-Sektion auf wiss-ki.eu (54,2%) und bewegen sich auf chat.wiss-ki.eu (50%), ein Drittel besucht www.arthistoricum.net/netzwerke/wisski und immerhin jeder Fünfte nimmt an weeklies teil, oder besucht die Drupal-Angebote. Unser Mastodon-Channel wird dagegen weniger genutzt.
Freuen können wir uns über eine Zustimmung zu WissKI, 60% der Befragten halten es für eher wahrscheinlich oder sehr wahrscheinlich, dass Sie WissKI weiterempfehlen würden. 16% Prozent könnten wir nicht überzeugen, für sie ist es sehr unwahrscheinlich oder eher unwahrscheinlich, dass sie WissKI weiterempfehlen.
Über digitale Langzeitarchivierung von und mit WissKI informierte Robert Nasarek. (Präsentation)
Digitale Langzeitarchivierung besteht aus dem physischen Erhalt von Datenstrukturen und Datenträgern (Bitstream Preservation) und der Interpretierbarkeit von Inhalten (Content Preservation). Ein digitales Langzeitarchiv muss sich daher einerseits zu einer redundanten, dezentralen und fehlerfreien Speicherung fähig sein und signifikante Eigenschaften von Dokumenten und Medien bei einem fortlaufenden Technischen Wandel erhalten. Um dies zu erreichen muss das Content Management von WissKI durch die Funktionen einer Dateiformat-Erkennung, -validierung und -migration, Archivpaketerstellung und -prüfung, und redundanten Speicherung erweitert werden.
WissKI selbst stellt robuste Systemexportformate bereit, um Daten und Strukturen zu erhalten. Die Drupaldatenbank und seine Konfigurationsstrukturen lassen sich als SQL- bzw. YML-Dateien, der Pathbuilder als XML und der Triplestore als N-Quads exportieren, allesamt ASCII-enkodierte Textdateien, einem langzeitarchivfähigem Format. Mit Software wie dem WissKI Viewer können mit einer Pathbuilder-XML, Triplestore N-Quad-Datei und den Drupal-Public-Ordner (Speicherort für Dokumente und Medien) auch Inhalte ohne Drupal/WissKI-Instanz einfach ausgelesen werden. Dies stellt eine enorme Vereinfachung für die Langzeitarchivierung eines WissKIs dar.
Einen ersten Einblick in die WissKI Cloud gewährte Robert Nasarek.
Ende des Jahres startet die WissKI Cloud, um WissKI-Interessierten eine einfache Möglichkeit zu bieten, eine WissKI-Instanz aufzusetzen, die über alle nötigen Module und Einstellungen verfügt direkt loszulegen. Nutzer*innen registieren sich auf https://www.wisski.cloud und erhalten eine in Speicherplatz und Ressourcen limitierte WissKI-Instanz zum reinschnuppern und semantischen Probemodellieren. Produktivsysteme können weiterhin über den IGSD e. V. beantragt werden.
Lena Schneider schaute nach viereinhalb Jahren Projektzeit von Böhler re:search auf die Stärken und Schwächen von WissKI für die Provinienzforschung. (Präsentation)
Das Projekt Böhler re:search erschließt seit 2017 die Objekt- und Kundenkartei und die Fotomappen der Kunsthandlung Julius Böhler.
Anhand konkreter Fallbeispiele wurde gezeigt, dass dank der Flexibilität der Datenbankstruktur auf viele Besonderheiten und spezifische Anforderungen des Archivmaterials problemlos reagiert werden konnte. Gleichzeitig wurden neben den unbestreitbaren Vorteilen des semantischen Datenmodells auch konkrete Grenzfälle vorgestellt, die zeigen, dass das heterogene Quellenmaterial in manchen Konstellationen nicht mit dem System kompatibel ist und die Vorgänge folglich nur mit einer redaktionellen Bemerkung dem Nutzer erläutert werden können.
Am Beispiel des Deutschen Kunstarchivs erklärte Kathrin Fischeidl, wie Solr im WissKI-Kontext eingesetzt wird. (Präsentation)
Solr ist bekannt als performanter und zuverlässiger Such-Server und ermöglicht Volltext- und facettierte Suchen mithilfe von Indices. Weil bei der Onlinestellung verschiedene rechtliche Aspekt beachtet werden müssen, dürfen im Deutschen Kunstarchiv nicht alle Datensätze bzw. alle Felder innerhalb der Datensätze online einsehbar sein. Mithilfe der vier Bausteine 'Viewmode mit den gewünschten Feldern', 'Solr', 'View mit Filterkriterien' und 'WissKI Links in der Anzeige ersetzen' konnte diese Anforderung umgesetzt werden.
WissKI ist ein bedeutender Teil der Infrastruktur des Mitte November gestarteten Projekts "Sammlungen, Objekte, Datenkompetenzen (SODa)". Udo Andraschke umriss das Projekt, seine Aufgaben und Ziele. (Präsentation)
Das vom BMBF geförderte Projekt zielt darauf ab, die Digitalisierung von wissenschaftlichen Sammlungen an Hochschulen und Universitäten zu unterstützen, indem es Datenkompetenzen vermittelt und dabei hilft, datengetriebene Sammlungs- und Objektforschung zu betreiben. SODa sieht sich als Nutzerorientiertes Datenkompetenzzentrum, das Digitalisierungsprojekte berät und unterstützt, relevante Methoden und Verfahren vermittelt und verschiedene Akteure vernetzt. Es bietet verschiedene Formate wie Online-Kurse, Workshops und Foren an und stellt eine zentrale Infrastruktur in Form eines Semantic Coworking Space zur Verfügung.
Den zweiten Teil des ersten Tages eröffnete Michael Kohlhase mit einer Einführung in das Competence Center for Research Data and Information (CDI) der Friedrich-Alexander-Universität Erlangen-Nürnberg.
Das CDI ist eine Einrichtung, die sich auf die Unterstützung von Wissenschaftlern bei der Verwaltung ihrer Forschungsdaten konzentriert. Das Zentrum bietet Schulungen, Ressourcen und Beratung zu Themen wie Datenmanagement, Datensicherung, Datenpublikation und -austausch an. Es fördert die Anwendung von Best Practices für den Umgang mit Forschungsdaten, um die Nachhaltigkeit, Zugänglichkeit und Wiederverwendbarkeit dieser Daten zu gewährleisten.
In diesem Kontext betreut es duzende WissKI-Instanzen, darunter Objekte im Netz, erstellt Umgebungen wie die FAUWissKICloud mit der WissKI Distillery, entwickelt Tools wie den WissKI Data Viewer, oder Module wie die WissKI Fire Brigade, WissKI Permalinks oder WissKI Statistics.
Tom Wiesing erläuterte, was nach WissKI übrig bleibt: Hangover und Headache. (Präsentation)
WissKI-Daten, die als Tripel in einer Graphdatenbank und als Metadaten in einem Pathbuilder gespeichert sind, werden regelmäßig zur Sicherung und Archivierung exportiert. Die Darstellung dieser Daten ist jedoch ohne eine laufende WissKI-Instanz aufwendig und eine Pflege eines WissKI-Systems erfordert erhebliche technische Fähigkeiten. Wenn ein WissKI-basiertes Projekt endet und die Finanzierung ausläuft, besteht die Gefahr, dass die Server-Infrastruktur wegfällt oder das System durch mangelnde Wartung unbrauchbar wird und es verbleiben nur archivierte Exporte der Daten. Der WissKI Data Viewer (aka Hangover/ Headache) stellt mit Hilfe der archivierten N-Quads, dem Pathbuilder und Content-Dateien die Möglichkeit bereit, auch ohne laufende WissKI/Drupal-Instanz Daten im ursprünglichen Datenmodell darzustellen. Zur Demo.
Am Beispiel der Informatik-Sammlung Erlangen (ISER) zeigte Elias Günther beispielhaft die Migration von WissKI. (Präsentation)
Die Aufgabe bestand darin, sowohl die Umgebung von Drupal 8 nach Drupal 10 mit allen Abhängigkeiten zu portieren, als auch die CIDOC-CRM Version auf die neueste ISO-Zertifizierte Version zu bringen.
Kai Amann präsentierte mit der WissKI API eine neue Form des Datenimports, -exports und der Datenbearbeitung. (Präsentation)
Die WissKI API ermöglicht den Im- und Export von Daten wie SQL, CSV und Excel Tabellen, die oft bei Systemmigrationen oder Datenaktualisierungen benötigt werden. Bisher erforderte dies einen hohen technischen Aufwand über die ODBC-Schnittstelle. Die WissKI API, eine generische REST-Schnittstelle, macht diese Aufgabe einfacher und ermöglicht auch den Import und Export von Konfigurationen wie dem Pathbuilder. Mit einer Python-Bibliothek können Inhalte programmatisch erstellt, bearbeitet und gelöscht werden. In Zukunft könnte die WissKI API den Datenaustausch mit Datenbereinigungssoftware wie OpenRefine ermöglichen oder zur automatischen Befüllung neuer WissKI-Systeme mit Beispieldaten dienen.
Im März 2023 startete NFDI4Objects. Sarah Wagner stellte die Struktur und Aufgaben des Konsortiums kurz vor. Das CDI ist dort in TA6 "Commons and Qualification" mit WissKIvertreten. (Präsentation)
NFDI4Objects fokussiert sich auf Forschungsdaten zu physischen Objekten. Das Konsortium setzt sich für die Etablierung von Standards für Dokumentation und Austausch dieser Daten ein und unterstützt die Entwicklung von Tools für eine bessere Zusammenarbeit zwischen den Disziplinen. Ziel ist es, Daten zugänglicher und nutzbarer zu machen, insbesondere für die Archäologie, die Kultur- und Geowissenschaften.
In diesem Kontext entwickelt das CDI die NFDI4Objects CoreOntology (basierend auf dem CIDOC CRM). In WissKI wird auf Grundlage der CoreOntology ein Knowledge Graph zur Repräsentation der Kerndaten von Objekten (ObjectCore) und einer für Objektbiografien (ObjectBiography) entwickelt und implementiert. Anhand von Use Cases von Objekten aus vielfältigen Sammlungsbereichen und Disziplinen erfolgt ein proof of concept.
Der zweite Tag bestand aus Workshops für WissKI Beginner*innen und einem parallel stattfindenden Barcamp for fortgeschrittene Nutzer*innen.
In den Workshops gab Mark Fichtner eine Einführung in WissKI, in die semantische Datenmodellierung
und die Konfiguration für speziellere Anwendungsszenarien (2D, 3D, Performance-Tuning).
Im Barcamp wurden Themen, Probleme und Lösungen aus den den Projekten der Teilnehmenden besprochen. Vor allem mit den Bereichen Dokumentation, Massenbearbeitung (Bulk Edit), Solr, Mehrsprachigkeit und Theming wurde sich eingehender beschäftigt.